
🌌 当AI开始"脑补":语言模型的推理困境
"拿破仑是法国人,因此他一定爱吃可颂面包。"这个看似合理的推理,实则暴露了语言模型(LLM)的致命软肋——证明偏差(Attestation Bias)。就像人类会因刻板印象产生认知偏差,LLM在自然语言推理(NLI)任务中,往往过度依赖训练数据中的记忆片段,而非真正理解前提与结论的逻辑关系。
剑桥大学团队的最新研究发现,当面对"乔治·布什曾担任得州州长 ⇒ 乔治·布什是得州政治家"这类推理时,主流LLM的准确率高达92%。但若将前提改为"乔治·布什住在得州",模型仍会以78%的概率给出肯定判断。这种"记忆优先于逻辑"的现象,就像让福尔摩斯破案时只查阅名人档案而不勘察现场证据。
证明偏差的本质:AttBias = P(Entail|Att) - P(Entail|¬Att)
其中Att表示假设在训练数据中被"证明"过。该指标量化了模型对记忆的依赖程度。
🛠️ 构建逻辑的"净化装置":蕴含图技术
研究团队开发了一套认知偏差矫正系统,其核心是蕴含图(Entailment Graphs)的构建与应用。这个过程犹如为AI打造逻辑思维的脚手架:
graph TD
A[海量文本] --> B(语义解析)
B --> C[谓词-类型三元组]
C --> D{分布相似性计算}
D --> E[正向蕴含关系]
D --> F[负向非蕴含关系]
E --> G[蕴含图网络]
F --> G
G --> H[反事实实例化]
H --> I[训练数据集]
🔍 知识蒸馏四部曲
- 语义解构:使用组合范畴语法(CCG)解析器,将句子拆解为<主体,谓词,客体>的三元组结构
- 类型锚定:通过实体链接将"拿破仑"映射为<人物>类型,"法国"标记为<地点>
- 关系编织:计算"担任州长→是政治家"的共现概率,形成蕴含边
- 反事实生成:用随机实体实例化类型模板,如"特斯拉创始人曾任巴黎州长 ⇒ 是巴黎政治家"
这种方法的精妙之处在于,它打破了传统NLI数据集的结构性偏差。就像用乐高积木搭建虚拟城市——基础模块来自现实,但组合方式完全创新,迫使模型学习抽象的逻辑规则而非具体事实。
📊 认知偏差的"解毒"实验
实验设计双维度
评估维度核心方法关键指标
偏差削减随机前提推理任务(RPI)AttBias下降幅度
推理能力偏差中和测试集(LHrpArg)AUC提升值
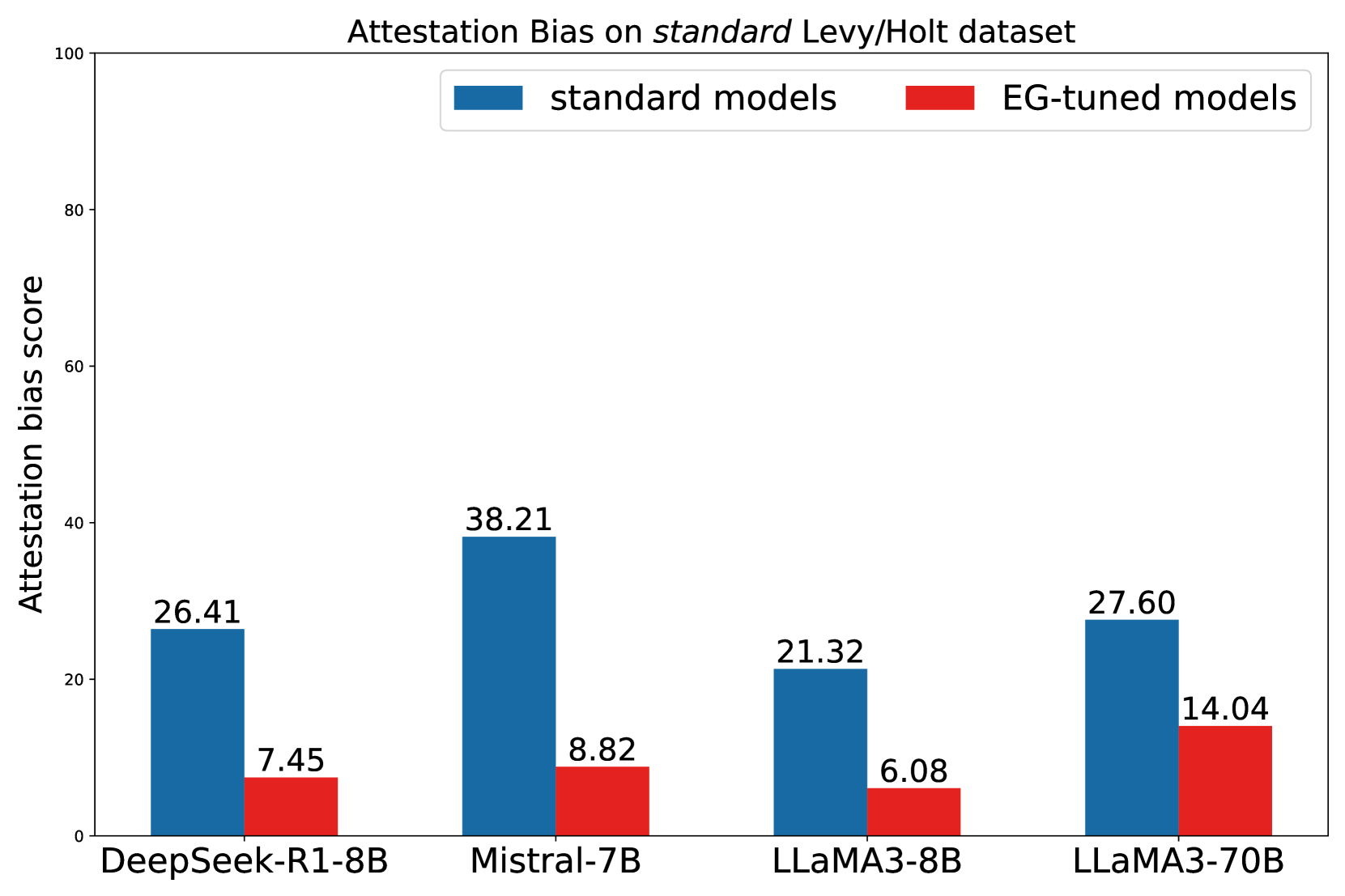
在7B到70B参数的不同规模模型测试中,EG增强技术展现出惊人效果:
- Mistral-7B的AttBias从32.98降至13.0
- 在涉及高频实体的LHrpArg↑测试集上,LLaMA-8B的AUC提升11.91%
- 经过EG训练的7B模型,推理能力可匹敌原始70B模型
"这就像给模型戴上了逻辑矫正眼镜,"论文第一作者程亮比喻道,"它们开始学会区分'已知事实'与'当前语境',就像人类侦探区分档案记录和现场证据。"
🌐 推理革命的启示与挑战
这项突破带来的不仅是技术改进,更揭示了AI认知进化的新路径:
- 知识解耦:将事实记忆与推理能力分离,构建模块化认知架构
- 反事实思维:通过虚拟场景训练,增强模型的假设推演能力
- 偏差免疫:建立逻辑"防火墙",降低数据偏见对决策链的影响
但挑战依然存在:
- 当前方法局限于NLI任务,泛化到问答、摘要等场景仍需探索
- 大规模蕴含图构建的计算成本较高
- 如何处理模糊语义边界(如"运营公司"vs"运营软件")仍是难点
正如17世纪炼金术向现代化学的蜕变,这项研究标志着AI从"数据炼金"向"逻辑冶炼"的关键转折。当语言模型真正学会区分记忆与推理,或许我们就能见证机器智能的"启蒙运动"。
参考文献
- Cheng, L., et al. (2023). Neutralizing Bias in LLM Reasoning using Entailment Graphs. 预印本.
- Mckenna, N., et al. (2023). Attestation Bias in Large Language Models. ACL会议论文集.
- Hosseini, M.J., et al. (2021). Scalable Construction of Entailment Graphs. 计算语言学协会汇刊.
- Poliak, A., et al. (2018). Hypothesis-Only Baselines in NLI. 自然语言处理实证方法会议.
- Bowman, S.R., et al. (2015). SNLI数据集:自然语言推理的基准. 计算语言学协会汇刊.