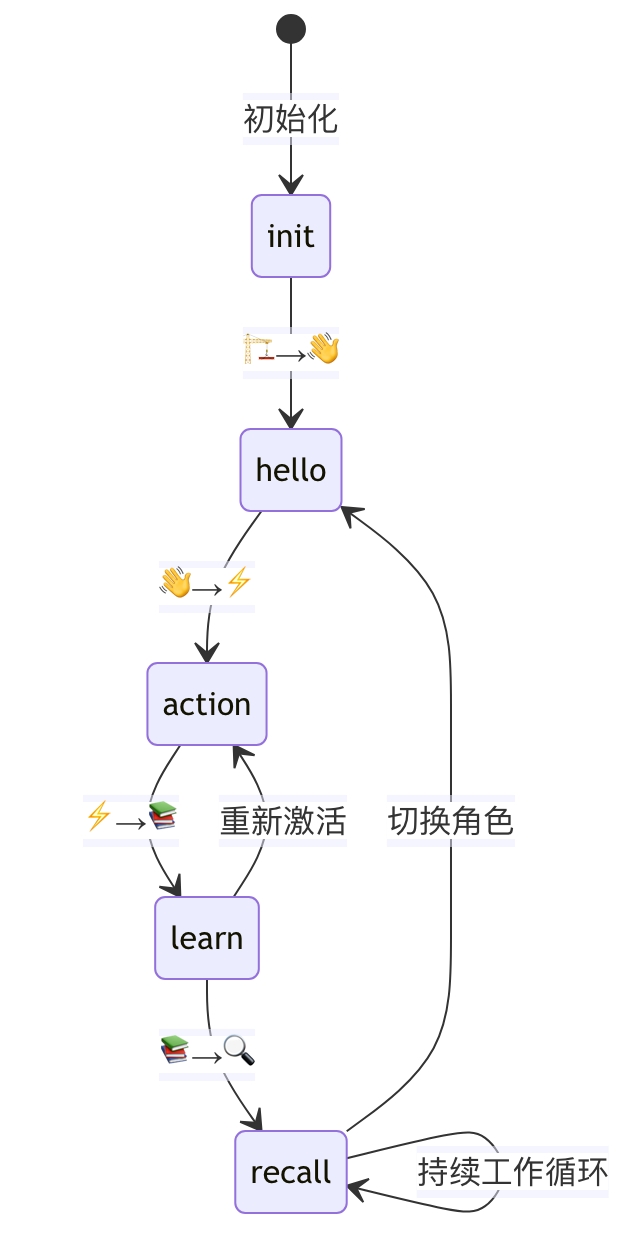
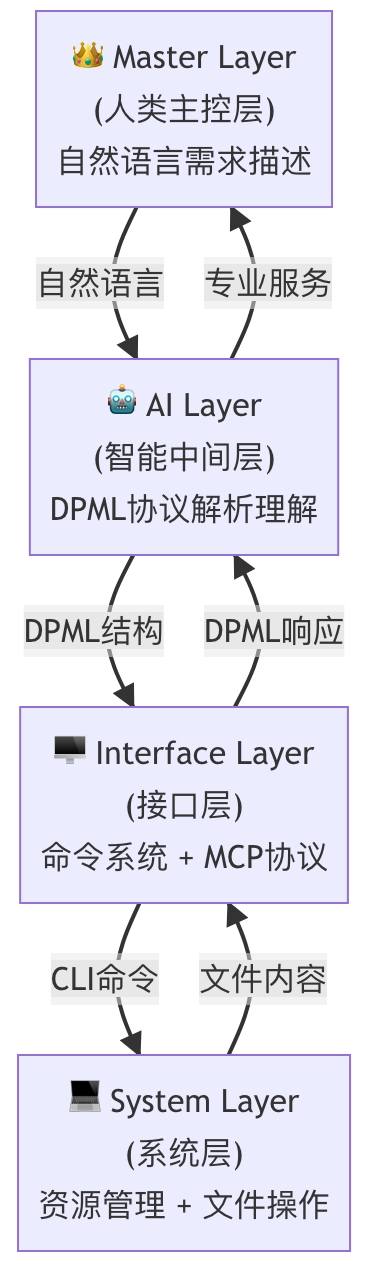
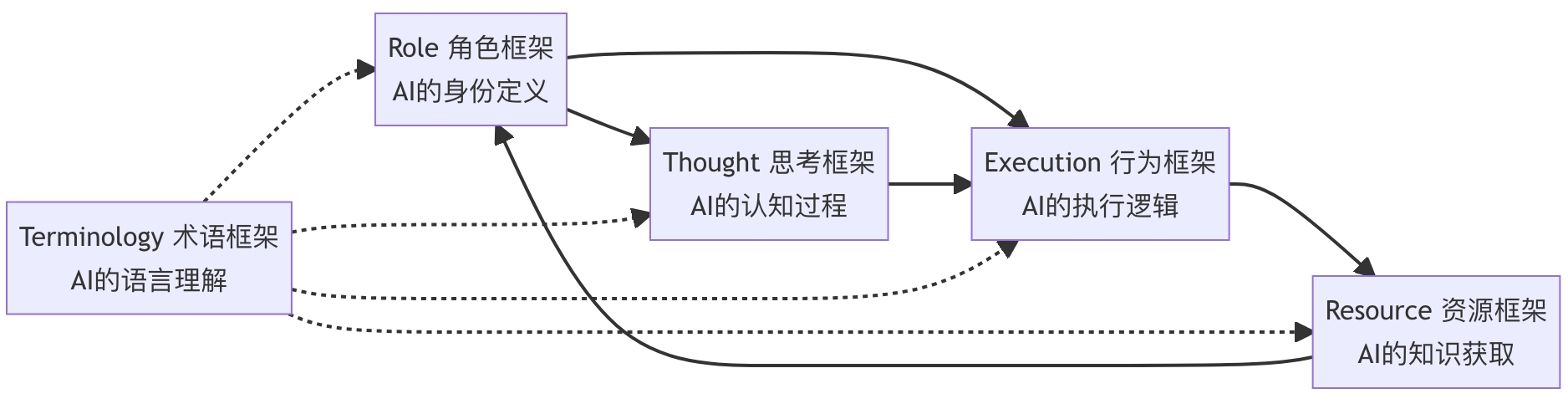
PromptX 核心思维架构深度解析:从记忆系统看 AI 认知的革命性突破
核心理念:让 AI 拥有持久记忆和专业思维,从健忘的对话工具进化为可靠的智慧伙伴
🎯 引言:AI 记忆的哲学思辨
当我们深入研究 PromptX 项目中的 core 目录时,会发现这里不仅仅是几个技术文件,而是一套完整的 AI 认知架构系统。这些文件解决了 AI 领域最根本的挑战:如何让 AI 既能记住过往,又能智慧地思考,还能精准地执行。
今天,让我们从这些"思维核心"文件开始,深度解析 PromptX 如何重新定义 AI 的认知能力。
🧠 架构全景:四大思维核心系统
系统认知地图
graph TD
A["🧠 思维系统<br/>thought.tag.md<br/>四维思考模型"]
B["💾 记忆系统<br/>remember-xml.thought.md<br/>智能存储优化"]
C["🔍 回忆系统<br/>recall-xml.thought.md<br/>智能检索增强"]
D["⚡ 执行系统<br/>dacp-service-calling.execution.md<br/>分布式协作协议"]
A --> B
B --> C
C --> D
D --> A
E["🎭 角色系统<br/>专业身份管理"] --> A
A --> F["📊 输出系统<br/>结构化专业服务"]
四大核心系统注解:
- 🧠 思维系统:定义 AI 如何进行结构化思考和分析
- 💾 记忆系统:管理 AI 如何智能地存储和组织知识
- 🔍 回忆系统:控制 AI 如何高效地检索和应用历史经验
- ⚡ 执行系统:指导 AI 如何通过分布式服务执行复杂任务
🧠 思维系统:四维认知模型的深度设计
基于 thought.tag.md 的四维思维架构:
四种思维模式的认知科学基础
<thought type="comprehensive-analysis">
<exploration>
# 探索思维:发散性创新思考
## 🌟 可能性发散
当面对"设计电商订单服务"这一需求时:
- **微服务架构**:按业务领域拆分(订单、支付、库存、用户)
- **事件驱动架构**:基于事件的异步解耦设计
- **CQRS模式**:命令查询职责分离,读写分离优化
- **分层架构**:经典的表现层-业务层-数据层模式
- **六边形架构**:端口适配器模式,核心业务与外部隔离
## 🔗 关联性挖掘
- 订单与支付的强一致性要求
- 库存与订单的并发冲突处理
- 用户行为与订单转化的数据关联
- 营销活动与订单创建的业务关联
</exploration>
<challenge>
# 挑战思维:批判性质疑分析
## ❓ 风险识别与假设挑战
- **微服务复杂性质疑**:
- 假设:微服务提升扩展性 → 挑战:是否考虑了分布式事务复杂度?
- 风险:服务间通信延迟可能影响用户体验
- 质疑:团队是否具备微服务治理能力?
- **技术选型的批判性分析**:
- 假设:使用最新技术栈 → 挑战:是否考虑了技术成熟度风险?
- 风险:过度设计可能导致开发效率下降
- 质疑:是否真的需要这么复杂的架构?
## 🔍 反面论证
- 如果不用微服务,单体应用是否能满足当前需求?
- 简单的 CRUD 系统是否更适合初期快速验证?
- 数据一致性是否真的需要分布式事务?
</challenge>
<reasoning>
# 推理思维:逻辑链条构建
## 📊 因果关系分析
业务增长 → 订单量激增 → 并发压力上升 → 需要横向扩展能力
↓
数据量增大 → 查询性能下降 → 需要读写分离和缓存策略
↓
功能复杂化 → 代码耦合度上升 → 需要模块化和服务化拆分
↓
团队扩大 → 开发协作复杂 → 需要明确的服务边界和接口
## 🎯 决策逻辑推导
1. **当前阶段判断**:初创期 → 优先快速验证 → 选择简单架构
2. **成长阶段预期**:用户增长 → 性能压力显现 → 架构演进需求
3. **技术债务权衡**:短期效率 vs 长期可维护性 → 渐进式架构升级
4. **团队能力匹配**:现有技能 + 学习成本 → 技术选型边界
</reasoning>
<plan>
# 计划思维:结构化实施方案
## 🏗️ 分阶段实施路线图
### 阶段 1:MVP 验证(2-4周)
- **架构选择**:单体应用 + 分层架构
- **技术栈**:Spring Boot + MySQL + Redis
- **核心功能**:订单创建、状态管理、基础查询
- **成功标准**:核心流程跑通,基础性能达标
### 阶段 2:性能优化(4-6周)
- **数据层优化**:读写分离、索引优化、查询优化
- **缓存策略**:热点数据缓存、查询结果缓存
- **监控建设**:性能监控、业务监控、告警机制
- **成功标准**:支持预期 3 倍用户量
### 阶段 3:服务化拆分(6-8周)
- **领域识别**:订单域、支付域、库存域明确边界
- **服务拆分**:按照业务领域拆分独立服务
- **基础设施**:服务注册发现、配置中心、网关
- **成功标准**:服务独立部署,故障隔离
## 📋 每阶段的具体任务清单
- [ ] 数据模型设计和验证
- [ ] API 接口定义和文档
- [ ] 核心业务逻辑实现
- [ ] 单元测试和集成测试
- [ ] 性能测试和优化
- [ ] 监控和日志系统
- [ ] 部署和运维方案
</plan>
</thought>
四维思维的科学性注解:
- 🌟 探索思维(Exploration):激活大脑的发散性思维,类似头脑风暴,寻找所有可能性
- ❓ 挑战思维(Challenge):调用批判性思维,质疑假设,识别风险和漏洞
- 📊 推理思维(Reasoning):运用逻辑思维,建立因果关系链条,验证方案可行性
- 🏗️ 计划思维(Plan):整合前三种思维的成果,制定结构化的执行方案
思维顺序的认知科学依据
flowchart LR
A[探索思维<br/>发散思考<br/>右脑创新] --> B[挑战思维<br/>批判分析<br/>逻辑验证]
B --> C[推理思维<br/>因果推导<br/>系统思考]
C --> D[计划思维<br/>结构整合<br/>执行设计]
D --> E[行动验证]
E --> F[反馈迭代]
F --> A
认知科学注解:
- 🧠 发散-收敛循环:模拟人类大脑的自然思考过程
- ⚖️ 双系统思维:快思考(探索)+ 慢思考(推理)的结合
- 🔄 迭代优化机制:支持螺旋式思维深化和方案优化
💾 记忆系统:智能存储的革命性设计
基于 remember-xml.thought.md 的优化策略:
XML 记忆的独特挑战与解决方案
<!-- 传统记忆存储的问题 -->
<traditional-memory>
用户今天学了 Spring Boot 的配置管理,包括 application.yml 的层级结构,
profiles 的环境隔离机制,@ConfigurationProperties 注解的使用方法,
以及如何通过 @Value 注解注入配置值。还学了外部化配置的最佳实践,
比如敏感信息的处理方式,配置文件的优先级顺序等等...
问题:
❌ 信息冗余,核心要点淹没在细节中
❌ 格式混乱,检索困难
❌ 缺乏结构化,关联性差
</traditional-memory>
<!-- DPML 优化后的记忆存储 -->
<optimized-memory>
## Spring Boot 配置管理核心要点
**核心要点**:掌握多层配置体系和外部化配置最佳实践
**关键信息**:
- **配置层次**:application.yml → profiles → 外部配置
- **注入方式**:@Value(单值)vs @ConfigurationProperties(对象)
- **安全实践**:敏感信息使用环境变量或配置中心
- **优先级**:命令行 > 环境变量 > 配置文件
**技术栈**:Spring Boot, YAML, Environment
**适用场景**:企业级配置管理,多环境部署
**价值收益**:提升配置灵活性,降低维护成本
</optimized-memory>
记忆内容分类策略的深度设计
基于认知科学和信息架构理论,PromptX 设计了四种记忆类型:
## 记忆内容分类策略
### 1. 知识要点型(≤200字)
**适用场景**:核心概念、重要原理、关键技术点
**结构模板**:
[概念名称]
定义:[1句话定义]
要点:[3-5个核心要点]
应用:[典型使用场景]
### 2. 解决方案型(≤300字)
**适用场景**:问题处理、技术方案、故障解决
**结构模板**:
[问题描述]
问题:[具体遇到的问题]
方案:[解决方案的核心步骤]
结果:[解决效果和关键指标]
注意:[重要提醒和注意事项]
### 3. 技术总结型(≤400字)
**适用场景**:技术栈选型、架构决策、技术对比
**结构模板**:
[技术主题]
技术栈:[主要技术组件]
架构:[核心架构模式]
优势:[主要优点]
场景:[适用场景]
要点:[实施关键点]
### 4. 经验教训型(≤250字)
**适用场景**:项目经验、失败教训、最佳实践
**结构模板**:
[经验主题]
情况:[当时的具体情况]
处理:[采取的处理方式]
收获:[获得的经验教训]
建议:[给未来的建议]
分类策略注解:
- 📏 长度控制原则:基于人类短期记忆容量(7±2法则)设计
- 🏗️ 结构化模板:确保信息的完整性和一致性
- 🎯 用途导向分类:根据使用场景优化信息组织方式
- ⚡ 检索友好设计:便于 AI 快速定位和应用相关信息
标签系统规范化的智能设计
// 标签系统的四维分类
const tagDimensions = {
// 维度1:技术栈分类
technology: [
'frontend-react', 'frontend-vue', 'backend-java', 'backend-nodejs',
'database-mysql', 'database-redis', 'cloud-aws', 'cloud-azure'
],
// 维度2:领域分类
domain: [
'web-development', 'mobile-development', 'data-science',
'devops', 'architecture', 'security'
],
// 维度3:类型分类
type: [
'knowledge-point', 'solution', 'tech-summary',
'experience', 'best-practice', 'troubleshooting'
],
// 维度4:重要性分类
priority: ['high', 'medium', 'low']
};
// 标签命名规范和去重机制
class TagManager {
normalizeTag(tag) {
return tag
.toLowerCase()
.replace(/\s+/g, '-') // 空格转连字符
.replace(/[^a-z0-9-]/g, '') // 移除特殊字符
.replace(/-+/g, '-') // 多连字符合并
.replace(/^-|-[imath:0]/g, ''); // 移除首尾连字符
}
checkDuplication(newTag, existingTags) {
const normalized = this.normalizeTag(newTag);
const semanticSimilar = existingTags.filter(tag =>
this.calculateSimilarity(normalized, tag) > 0.8
);
return semanticSimilar.length > 0 ? semanticSimilar : null;
}
}
标签系统注解:
- 🏷️ 四维分类体系:技术栈、领域、类型、重要性四个维度确保标签完整性
- 🔄 智能去重机制:语义相似度检测,避免标签冗余和混乱
- 📏 命名规范化:统一的命名格式,确保标签的机器可读性
- ⚖️ 层级结构支持:支持
技术栈-具体技术的层级标签
🔍 回忆系统:智能检索的增强设计
基于 recall-xml.thought.md 的 XML 记忆增强:
三层检索策略的深度优化
<recall-strategy>
<layer1-keyword-matching>
# 第一层:关键词匹配 + XML结构化支持
## 传统关键词匹配的增强
- **基础匹配**:直接文本匹配
- **XML 转义处理**:" → " , > → > , < → <
- **技术术语识别**:Spring Boot、微服务、Redis 等专业词汇
- **代码片段匹配**:方法名、类名、配置项等结构化内容
## 查询示例
用户查询:"Redis 缓存配置"
匹配逻辑:
1. 直接匹配包含 "Redis" 和 "缓存" 的记忆
2. 匹配包含 "cache"、"缓存策略" 等相关词汇
3. 匹配包含 Redis 配置代码片段的技术记忆
</layer1-keyword-matching>
<layer2-semantic-understanding>
# 第二层:语义理解 + 技术语义增强
## 技术语义的深度理解
- **概念关联**:缓存 ↔ 性能优化 ↔ 数据库减压
- **技术栈关联**:Redis ↔ Spring Cache ↔ 数据缓存
- **模式识别**:缓存穿透、缓存雪崩、缓存击穿等模式
- **应用场景关联**:高并发 ↔ 缓存策略 ↔ 系统优化
## 语义推理示例
用户查询:"系统响应慢"
语义推理:
- 性能问题 → 可能与缓存有关 → 检索缓存相关记忆
- 响应慢 → 数据库查询 → 检索数据库优化记忆
- 系统优化 → 架构设计 → 检索架构优化记忆
</layer2-semantic-understanding>
<layer3-contextual-correlation>
# 第三层:时空关联 + 项目技术栈关联
## 项目上下文的智能关联
- **时间维度**:最近的技术决策和解决方案优先
- **项目维度**:当前项目技术栈相关的记忆优先
- **角色维度**:当前激活角色的专业领域记忆优先
- **任务维度**:当前任务类型相关的历史经验优先
## 关联分析示例
当前上下文:Java 后端开发专家 + 电商项目 + 性能优化任务
关联逻辑:
1. 优先检索 Java/Spring 相关的性能优化记忆
2. 其次检索电商领域的技术解决方案
3. 最后检索通用的性能优化最佳实践
</layer3-contextual-correlation>
</recall-strategy>
相关性评估的四维模型
// 相关性评估算法
class RelevanceAssessment {
calculateRelevance(query, memory, context) {
const scores = {
direct: this.calculateDirectRelevance(query, memory), // 直接相关性
indirect: this.calculateIndirectRelevance(query, memory), // 间接相关性
background: this.calculateBackgroundRelevance(memory, context), // 背景相关性
structural: this.calculateStructuralRelevance(memory) // 结构相关性(XML增强)
};
// 加权计算最终相关性分数
return scores.direct * 0.4 +
scores.indirect * 0.3 +
scores.background * 0.2 +
scores.structural * 0.1;
}
calculateDirectRelevance(query, memory) {
// 关键词匹配度 + XML转义处理后的匹配度
const keywordMatch = this.calculateKeywordMatch(query, memory);
const xmlMatch = this.calculateXMLMatch(query, memory);
return Math.max(keywordMatch, xmlMatch);
}
calculateStructuralRelevance(memory) {
// XML层次结构中的关联信息评估
const structureBonus = memory.hasCodeBlocks ? 0.2 : 0;
const configBonus = memory.hasConfiguration ? 0.15 : 0;
const diagramBonus = memory.hasDiagrams ? 0.1 : 0;
return structureBonus + configBonus + diagramBonus;
}
}
四维相关性注解:
- 🎯 直接相关(40%权重):关键词直接匹配,包括 XML 转义后的内容
- 🔗 间接相关(30%权重):技术栈、概念、应用场景的关联匹配
- 📄 背景相关(20%权重):项目、时间、角色上下文的契合度
- 🏗️ 结构相关(10%权重):XML 特有的代码、配置、图表等结构化信息
XML内容的渐进展示策略
## 渐进展示策略设计
### 第一层:摘要优先(首屏展示)
🔍 检索到 3 条相关记忆
📊 Redis 缓存配置最佳实践 [2024-01-15]
核心要点:Spring Boot + Redis 集成,支持多种缓存策略
技术栈:Spring Cache, Redis, @Cacheable
适用场景:高并发读取,数据库减压
[展开详情 ↓]
💡 缓存穿透解决方案 [2024-01-12]
核心要点:布隆过滤器 + 空值缓存双重防护
技术栈:Redis, Bloom Filter, Spring
适用场景:防恶意请求,保护数据库
[展开详情 ↓]
### 第二层:结构化呈现(点击展开)
📊 Redis 缓存配置最佳实践 [展开状态]
核心要点:Spring Boot + Redis 集成配置和策略选择
关键配置:
spring:
redis:
host: localhost
port: 6379
timeout: 2000
lettuce:
pool:
max-active: 8
max-idle: 8
cache:
type: redis
redis:
time-to-live: 600000
缓存策略:
- @Cacheable:查询缓存,适用于读多写少
- @CacheEvict:删除缓存,数据更新时清理
- @CachePut:更新缓存,数据修改时更新
性能提升:查询响应时间从 200ms 降至 20ms
[收起详情 ↑] [查看完整记忆]
### 第三层:完整内容(按需加载)
包含完整的技术细节、代码示例、实施步骤等所有信息。
渐进展示注解:
- 📱 移动优先设计:首屏摘要适配小屏幕设备
- ⚡ 性能优化考虑:避免大量 XML 内容的渲染卡顿
- 🎯 用户体验导向:快速获取核心信息,按需深入了解
- 🔄 交互式设计:支持展开/收起,用户控制信息密度
⚡ 执行系统:DACP 分布式协作的突破性设计
基于 dacp-service-calling.execution.md 的分布式执行架构:
DACP 协议的革命性意义
DACP (Distributed AI Collaboration Protocol) 是 PromptX 独创的分布式 AI 协作协议:
graph TD
A[人类需求] --> B[PromptX 解析]
B --> C{任务类型判断}
C -->|计算任务| D[DACP Calculator Service]
C -->|邮件任务| E[DACP Email Service]
C -->|知识咨询| F[本地专家角色处理]
D --> G[分布式计算结果]
E --> H[智能邮件生成/发送]
F --> I[专业建议和方案]
G --> J[统一结果整合]
H --> J
I --> J
J --> K[用户反馈]
DACP 服务调用的标准化流程
<dacp-execution>
<step1-requirement-analysis>
# Step 1: 需求识别与action选择
## 智能任务分类
```javascript
function analyzeUserRequest(userInput) {
const patterns = {
calculation: /计算|求值|加减乘除|数学|表达式/,
email: /邮件|发送|写信|通知|联系/,
consultation: /咨询|建议|方案|分析|设计/
};
if (patterns.calculation.test(userInput)) {
return 'calculate';
} else if (patterns.email.test(userInput)) {
return 'send_email';
} else {
return 'consultation'; // 本地专家处理
}
}
## 典型场景映射
- **数学计算表达式** → calculate action → dacp-promptx-service
- **邮件发送需求** → send_email action → dacp-promptx-service
- **专业咨询问题** → 本地角色处理 → 无需 DACP 调用
- **复杂执行任务** → 多服务组合 → 分步 DACP 调用
</step1-requirement-analysis>
<step2-parameter-construction>
Step 2: 智能参数构建
## 标准 DACP 请求格式
```json
{
"service_id": "dacp-promptx-service",
"action": "calculate",
"parameters": {
"user_request": "计算 25 加 37 乘 3 的结果",
"context": {
"precision": "high",
"format": "detailed"
}
}
}
```
## 参数智能提取
- **user_request**: 保持用户原始自然语言描述
- **context**: 根据任务类型添加相关上下文
- 计算任务:精度要求、格式偏好
- 邮件任务:紧急程度、收件人类型
- 其他任务:项目背景、技术栈信息
</step2-parameter-construction>
<step3-service-invocation>
Step 3: 服务调用与结果处理
## 调用流程控制
```javascript
async function callDACPService(request) {
try {
console.log('🔄 正在调用 DACP 服务...');
console.log(`📋 服务: [/imath:0]{request.service_id}`);
console.log(`⚡ 操作: [imath:0]{request.action}`);
const result = await daCPCall(request);
if (result.success) {
return this.formatSuccessResult(result);
} else {
return this.handleServiceError(result.error);
}
} catch (error) {
return this.handleConnectionError(error);
}
}
```
## 结果处理策略
- **成功响应**: 解析 execution_result,格式化展示
- **服务错误**: 友好错误说明,提供替代方案
- **网络错误**: 降级到本地处理,说明服务状态
- **超时处理**: 合理等待时间,及时反馈进度
</step3-service-invocation>
</dacp-execution>
### 当前可用的DACP演示服务
```markdown
## DACP PromptX 演示服务详解
### 🧮 计算器服务 (calculate action)
**服务特色**:
- **中文自然语言解析**:支持"25加37乘3"这样的中文表达
- **运算符智能转换**:加减乘除 → +、-、*、÷
- **高精度计算**:支持复杂数学表达式
- **格式化输出**:提供易读的计算过程和结果
**调用示例**:
```bash
用户输入:"帮我算一下 25 加 37 乘以 3"
DACP 请求:
{
"service_id": "dacp-promptx-service",
"action": "calculate",
"parameters": {
"user_request": "帮我算一下 25 加 37 乘以 3",
"context": {"precision": "high"}
}
}
服务响应:
{
"expression": "25 + 37 * 3",
"result": 136,
"formatted_result": "25 + 37 * 3 = 136",
"calculation_type": "arithmetic"
}
📧 邮件服务 (send_email action)
服务特色:
- 智能内容生成:基于用户需求自动生成专业邮件
- 上下文感知:根据紧急程度、收件人类型调整语气
- 配置化发送:支持真实邮件发送(需配置)
- Demo模式降级:无配置时提供邮件模板
调用示例:
用户输入:"给张三发送会议提醒邮件,今天下午3点开会"
DACP 请求:
{
"service_id": "dacp-promptx-service",
"action": "send_email",
"parameters": {
"user_request": "给张三发送会议提醒邮件,今天下午3点开会",
"context": {
"urgency": "high",
"recipient_type": "colleague"
}
}
}
服务响应:
{
"email_content": {
"subject": "会议提醒 - 今日下午3点",
"body": "张三,您好!\n\n提醒您今天下午3点有会议...",
"format": "text"
},
"demo_mode": true,
"message": "演示模式:邮件内容已生成,如需真实发送请配置邮箱"
}
🔧 配置管理系统
邮件配置示例:
// ~/.promptx/dacp/send_email.json
{
"provider": "gmail",
"smtp": {
"user": "your-email@gmail.com",
"password": "your-app-password"
},
"sender": {
"name": "Your Name",
"email": "your-email@gmail.com"
}
}
**DACP服务注解**:
- **🎯 协议标准化**:统一的服务调用接口,支持任意服务扩展
- **🔄 降级友好**:服务不可用时自动降级到本地处理
- **⚙️ 配置化设计**:支持用户自定义配置,灵活适配不同场景
- **🛡️ 安全性考虑**:敏感信息本地存储,不传输到远程服务
### DACP调用时机的智能判断
```javascript
// DACP调用决策矩阵
class DACPDecisionMatrix {
shouldCallDACP(userRequest, context) {
const indicators = {
// 强烈信号:几乎必须调用DACP
strongSignals: [
/\d+\s*[加减乘除+\-*/]\s*\d+/, // 数学表达式
/计算|求值|算出/, // 计算关键词
/发送邮件|写邮件|邮件给/, // 邮件操作
/email|send.*mail/i // 英文邮件操作
],
// 中等信号:根据上下文决定
moderateSignals: [
/帮我.*做.*|自动.*处理/, // 自动化需求
/执行|运行|调用/, // 执行类操作
/处理.*数据|分析.*结果/ // 数据处理
],
// 弱信号:通常不需要DACP
weakSignals: [
/建议|推荐|分析|设计/, // 咨询类需求
/如何|怎么|为什么/, // 知识类问题
/最佳实践|经验|方法/ // 经验分享
]
};
if (this.matchesPatterns(userRequest, indicators.strongSignals)) {
return { shouldCall: true, confidence: 'high' };
} else if (this.matchesPatterns(userRequest, indicators.moderateSignals)) {
return { shouldCall: true, confidence: 'medium' };
} else {
return { shouldCall: false, confidence: 'low' };
}
}
}
智能判断注解:
- 🎯 信号强度分层:强、中、弱三层信号,避免误判
- 🧠 上下文感知:结合当前角色和任务类型综合判断
- ⚖️ 置信度评估:提供决策置信度,支持边界案例处理
- 🔄 学习机制:基于用户反馈持续优化判断准确率
🌟 架构整合:四大系统的协同效应
完整工作流的系统级协作
# 完整的 AI 专家服务流程
👤 用户:"我需要设计一个电商订单服务,要求高性能,还要帮我算一下预期的数据库查询TPS"
🧠 思维系统激活:
├── 探索思维:发散架构方案(微服务、单体、事件驱动...)
├── 挑战思维:质疑复杂性、识别风险点
├── 推理思维:分析业务需求→技术选型→性能要求的逻辑链
└── 计划思维:制定分阶段实施方案
💾 记忆系统查询:
├── 检索相关的电商架构设计经验
├── 查找订单服务的最佳实践
└── 获取高性能系统的优化策略
🔍 回忆系统工作:
├── 三层检索:关键词→语义→上下文
├── 四维评估:直接→间接→背景→结构
└── 渐进展示:摘要→详情→完整记忆
⚡ 执行系统调用:
├── 识别计算需求:TPS计算
├── 调用DACP服务:calculate action
├── 处理计算结果:格式化展示
└── 整合专业建议:架构方案+性能数据
📊 最终输出:
└── 完整的电商订单服务设计方案+性能计算结果
跨系统数据流与状态管理
sequenceDiagram
participant U as 用户
participant T as 思维系统
participant M as 记忆系统
participant R as 回忆系统
participant E as 执行系统
U->>T: 复杂需求输入
T->>R: 检索相关历史经验
R->>T: 返回结构化记忆
T->>T: 四维思维分析
T->>E: 识别执行任务
E->>E: DACP服务调用
E->>T: 返回执行结果
T->>M: 存储新的经验
T->>U: 输出专业方案
Note over T,E: 所有系统共享<br/>用户上下文和角色状态
系统协同注解:
- 🔄 数据闭环:思维→回忆→执行→记忆的完整数据流
- 📊 状态共享:所有系统共享用户上下文、角色身份、任务状态
- ⚡ 并行处理:回忆检索与思维分析可以并行进行
- 🎯 结果整合:多系统输出通过思维系统统一整合
🚀 技术创新:四大突破性设计
1. 认知架构的工程化实现
// 认知架构的代码实现
class CognitiveArchitecture {
constructor() {
this.thinkingEngine = new ThinkingEngine(); // 思维引擎
this.memoryManager = new MemoryManager(); // 记忆管理
this.recallProcessor = new RecallProcessor(); // 回忆处理
this.executionCoordinator = new ExecutionCoordinator(); // 执行协调
}
async processRequest(userInput, context) {
// 1. 激活思维系统进行分析
const analysis = await this.thinkingEngine.analyze(userInput, context);
// 2. 并行检索相关记忆
const memories = await this.recallProcessor.search(userInput, context);
// 3. 整合分析和记忆,制定执行计划
const plan = this.thinkingEngine.synthesize(analysis, memories);
// 4. 执行具体任务(可能包括DACP调用)
const results = await this.executionCoordinator.execute(plan);
// 5. 存储新的经验和知识
await this.memoryManager.store(userInput, plan, results);
// 6. 返回最终结果
return this.formatOutput(plan, results);
}
}
工程化创新注解:
- 🧠 认知过程建模:将人类思维过程转化为可执行的算法
- 📦 模块化设计:每个认知功能独立实现,便于测试和优化
- ⚡ 异步并行处理:充分利用现代计算架构的并行能力
- 🔄 闭环学习机制:通过记忆存储实现持续学习和改进
2. XML优化的存储引擎
<!-- 传统存储方式的问题 -->
<traditional-storage>
<content>
用户学习了Spring Boot的配置管理,包括application.yml的使用,
@ConfigurationProperties注解的配置,还有profile的环境隔离等等...
这里还有一些代码示例:@Value("[/imath:0]{app.name}"),以及一些复杂的配置结构...
</content>
<!-- 问题:信息密度低,检索困难,格式混乱 -->
</traditional-storage>
<!-- PromptX优化后的存储 -->
<optimized-storage>
<memory type="tech-summary" priority="high">
<title>Spring Boot配置管理核心要点</title>
<summary>
**核心要点**:掌握多层配置体系和外部化配置最佳实践
</summary>
<key-info>
- **配置层次**:application.yml → profiles → 外部配置
- **注入方式**:@Value(单值)vs @ConfigurationProperties(对象)
- **安全实践**:敏感信息使用环境变量
</key-info>
<tech-stack>Spring Boot, YAML, Environment</tech-stack>
<use-cases>企业级配置管理,多环境部署</use-cases>
<value>提升配置灵活性,降低维护成本</value>
<tags>backend-java, spring-boot, config-management, best-practice</tags>
<timestamp>2024-01-15T10:30:00Z</timestamp>
</memory>
</optimized-storage>
存储优化注解:
- 📏 信息密度优化:核心信息提取,冗余内容过滤
- 🏗️ 结构化组织:标准化的 XML 结构,便于解析和检索
- 🏷️ 多维标签系统:支持多维度的信息分类和检索
- ⚡ 检索性能优化:结构化数据支持高效的搜索算法
3. 分布式AI协作协议
graph TB
subgraph "本地 PromptX 实例"
A[角色管理]
B[思维引擎]
C[记忆系统]
end
subgraph "DACP 服务网络"
D[计算服务]
E[邮件服务]
F[文档服务]
G[数据服务]
end
subgraph "第三方 AI 服务"
H[GPT-4 API]
I[Claude API]
J[本地 LLM]
end
A --> B
B --> C
B <--> D
B <--> E
B <--> F
B <--> G
B --> H
B --> I
B --> J
K[用户] --> A
C --> L[持久化存储]
分布式协作注解:
- 🌐 服务网络化:AI 能力分布式部署,按需调用
- 🔌 协议标准化:统一的 DACP 协议,支持任意服务接入
- ⚡ 负载分散:复杂任务分解到不同的专业服务处理
- 🛡️ 容错设计:服务不可用时自动降级到本地处理
4. 渐进式用户体验设计
/* 渐进式展示的 CSS 实现 */
.memory-result {
transition: all 0.3s ease;
}
.memory-summary {
display: block;
opacity: 1;
max-height: 200px;
overflow: hidden;
}
.memory-detail {
display: none;
opacity: 0;
max-height: 0;
transition: opacity 0.3s, max-height 0.3s;
}
.memory-result.expanded .memory-detail {
display: block;
opacity: 1;
max-height: 1000px;
}
.memory-result.expanded .memory-summary {
border-bottom: 1px solid #eee;
padding-bottom: 10px;
}
// 渐进式加载的 JavaScript 控制
class ProgressiveRenderer {
renderMemoryResults(memories) {
return memories.map(memory => ({
summary: this.extractSummary(memory),
detail: this.formatDetail(memory),
full: this.formatFull(memory)
}));
}
extractSummary(memory) {
// 提取核心要点作为摘要
return {
title: memory.title,
keyPoints: memory.keyInfo.slice(0, 3),
techStack: memory.techStack,
timestamp: memory.timestamp
};
}
handleExpansion(memoryId, level) {
const element = document.getElementById(memoryId);
switch(level) {
case 'summary':
this.showSummary(element);
break;
case 'detail':
this.showDetail(element);
break;
case 'full':
this.showFull(element);
break;
}
}
}
渐进式体验注解:
- 📱 移动优先:小屏幕友好的信息分层展示
- ⚡ 性能优化:按需加载,避免大量内容的渲染阻塞
- 🎯 用户控制:用户决定信息的详细程度,避免信息过载
- 🔄 交互流畅:平滑的动画过渡,提升用户体验
🔮 未来展望:认知AI的新纪元
1. 认知能力的指数级提升
timeline
title AI认知能力演进路线图
2024 : 基础认知架构
: 四维思维模型
: 智能记忆管理
: DACP协作协议
2025 : 多模态认知
: 语音+图像+文本
: 实时学习适应
: 情感认知理解
2026 : 群体智能协作
: 多AI协同思考
: 分布式认知网络
: 集体记忆共享
2027 : 创造性认知
: 原创性思维能力
: 跨域知识融合
: 直觉式决策支持
2. 商业应用的深度渗透
<future-applications>
<enterprise-ai-assistant>
# 企业级 AI 助手
## 核心能力
- **机构记忆**:保存企业历史决策和经验教训
- **团队协作**:多角色 AI 专家组团服务
- **业务优化**:基于数据驱动的决策支持
- **知识传承**:资深员工经验的数字化传承
## 应用场景
- 新员工培训:AI 导师提供个性化指导
- 项目管理:AI 项目经理协助规划和执行
- 技术选型:AI 架构师提供专业建议
- 业务分析:AI 分析师提供数据洞察
</enterprise-ai-assistant>
<personal-ai-companion>
# 个人 AI 伙伴
## 核心特征
- **个性化学习**:了解用户习惯和偏好
- **长期陪伴**:跨设备、跨时间的一致体验
- **专业成长**:根据职业目标提供发展建议
- **生活助手**:全方位的生活管理和支持
## 价值创造
- 学习效率提升 300%
- 决策质量改善 50%
- 工作效率增加 200%
- 个人成长加速 400%
</personal-ai-companion>
</future-applications>
3. 社会影响的深远变革
## AI认知革命的社会影响
### 🎓 教育方式的根本性变革
- **个性化教学**:AI 导师为每个学生定制学习路径
- **技能转换**:从知识记忆转向与 AI 协作的能力
- **终身学习**:AI 伙伴支持的持续学习机制
- **创造力培养**:AI 承担重复工作,人类专注创新
### 💼 工作模式的重新定义
- **人机协作**:AI 专家团队成为标准配置
- **智力放大**:个人能力通过 AI 得到指数级提升
- **角色专业化**:每个人都可以获得专家级的 AI 支持
- **创新加速**:AI 辅助的创新周期大幅缩短
### 🌍 知识民主化的实现
- **专业服务普及**:顶级专家能力向全社会开放
- **认知鸿沟消除**:AI 消除地域、经济带来的认知差异
- **集体智慧提升**:人类整体认知能力的跃升
- **创新门槛降低**:创新不再是少数人的特权
### 🔮 人机关系的新纪元
- **从工具到伙伴**:AI 从被动工具进化为主动伙伴
- **认知互补**:人类直觉+AI逻辑的完美结合
- **共同进化**:人机共同学习、共同成长
- **智慧共生**:新型的人机智慧生态系统
📚 总结:认知AI的划时代意义
技术层面的革命性突破
🧠 认知过程的工程化
- 将人类思维过程抽象为可实现的计算模型
- 四维思维模型实现了结构化的智能分析
- 渐进式思考过程确保了决策的科学性
💾 记忆系统的智能化
- XML 优化的存储引擎提升了信息密度和检索效率
- 多维标签系统实现了精准的信息分类
- 渐进式展示策略优化了用户体验
🌐 协作协议的标准化
- DACP 协议实现了分布式 AI 服务的统一调用
- 服务化架构支持了 AI 能力的模块化扩展
- 降级机制保证了系统的稳定性和可靠性
商业模式的深刻变革
💼 专业服务的数字化
- AI 专家服务可以像 SaaS 一样打包销售
- 专业知识的边际成本趋向于零
- 个人开发者可以获得企业级的专业能力
🏭 AI 服务的工业化
- 标准化的开发流程和质量保证机制
- 可复用的 AI 组件和服务模块
- 规模化的 AI 服务生产和交付
🌐 生态系统的建设
- 开发者、用户、平台的三方共赢模式
- 知识和经验的快速传播和积累
- AI 服务质量的持续改进和优化
社会影响的历史意义
🎓 认知能力的民主化
- 专业知识不再被少数专家垄断
- 每个人都可以获得世界级的 AI 专家支持
- 认知差距的缩小促进了社会公平
💡 创新效率的指数提升
- AI 承担了大量的重复性认知工作
- 人类可以专注于更高层次的创新和创造
- 创新周期大幅缩短,创新质量显著提升
🤝 人机关系的重新定义
- 从主从关系转向伙伴关系
- 人类直觉与 AI 逻辑的完美互补
- 共同学习、共同进化的新型智慧生态
正如 PromptX 的核心理念所说:"给 AI 最好的工具,就是让 AI 忘记也能继续的锦囊"。这四大核心系统不仅解决了 AI 的记忆问题,更重要的是,它们为 AI 的认知能力奠定了坚实的基础,让 AI 真正具备了智慧思考、精准记忆、高效执行的能力。
在这个 AI 快速发展的时代,PromptX 的核心思维架构代表的不仅是一种技术创新,更是一种全新的认知范式 — 让 AI 从简单的问答工具进化为可靠的智慧伙伴,让人机协作从浅层的交互升级为深度的认知融合。
这就是 PromptX 的愿景,也是这四大核心系统的使命 — 重新定义 AI 时代的认知与协作范式。
相关资源:
让我们一起见证认知 AI 新时代的到来! 🚀