在浩瀚的科技星空中,图像匹配技术犹如一座连接不同星系的桥梁。无论是医疗影像、遥感监测、组织病理学,还是自动驾驶和机器人导航,准确匹配不同模态下的图像关键信息都扮演着至关重要的角色。今天,我们将带您走进一项前沿技术的世界——基于大规模预训练的通用跨模态图像匹配(MatchAnything),见证智能算法如何跨越成像原理的鸿沟,实现“万物皆可匹配”的奇迹。
本文将以一种生动而风趣的叙述方式,逐步揭开这项技术的神秘面纱,从理论、方法、实验再到未来展望,带您领略跨模态匹配的美妙世界。文章不仅涵盖了论文中提及的所有关键点,还穿插了形象的比喻与生动的例子。让我们从最初的疑惑和困惑,到最后的技术突破,一起探索这段充满科学与艺术碰撞的奇妙之旅吧!
 跨模态图像匹配:从微观结构到宏观应用
跨模态图像匹配:从微观结构到宏观应用
跨模态图像匹配任务,顾名思义,就是在不同成像原理下获取的图像之间寻找准确的对应关系。设想一下,一位天文爱好者用肉眼观察星空,在望远镜下却能捕捉到无数细节;同样,在医疗领域,一位医生可能需要将 CT、MR、PET、SPECT 等不同影像完美对齐,以获得全面的诊断信息。不同模态下的图像因成像原理不同,外观可能有天壤之别,但它们同样蕴藏着描述同一物理结构的内在规律。如何在这些看似“天马行空”的差异中,找到那条贯穿始终的“本质线索”?这正是跨模态图像匹配所要解决的核心问题。
传统的方法通常依赖于人工设计的关键点检测与描述子提取手段,但这些方法在面对模态之间出现巨大外观差异时往往力不从心。例如,在组织病理学中,不同染色方法(如 H&E 与 IHC)的图像具有显著的颜色和纹理差异,人工标注不仅耗时费力,还难以捕捉到微妙的结构信息。与此同时,依赖于深度学习的检测器(detector-based)虽然在单模态匹配任务上表现惊人,但在跨模态场景下也常常遭遇“识别盲区”。于是,研究者们开始探索基于 Transformer 的检测器自由(detector-free)匹配方法,直接在像素层面进行匹配,从而跳过初期关键点提取带来的噪声问题。
在这一背景下,MatchAnything 项目应运而生。其目标不仅是解决跨模态匹配的技术难题,更希望构建一个具备普适性、能够应用到多种领域的通用图像匹配系统。正如搭建一座连接不同星系的桥梁,该系统致力于让计算机在面对从遥感到医疗的各种数据时,都能一眼洞察结构性信息,实现准确匹配。
 走近核心:大规模预训练框架的魔法原理
走近核心:大规模预训练框架的魔法原理
要使图像匹配算法具备如此强大的通用性,最重要的一环在于数据的多样性与预训练策略的巧妙设计。MatchAnything 团队提出了一种大规模跨模态预训练框架,这一框架不仅融合了多种数据资源,还通过生成合成跨模态训练信号,提高了模型在未见任务中的泛化能力。
 多资源数据融合——千锤百炼的训练样本
多资源数据融合——千锤百炼的训练样本
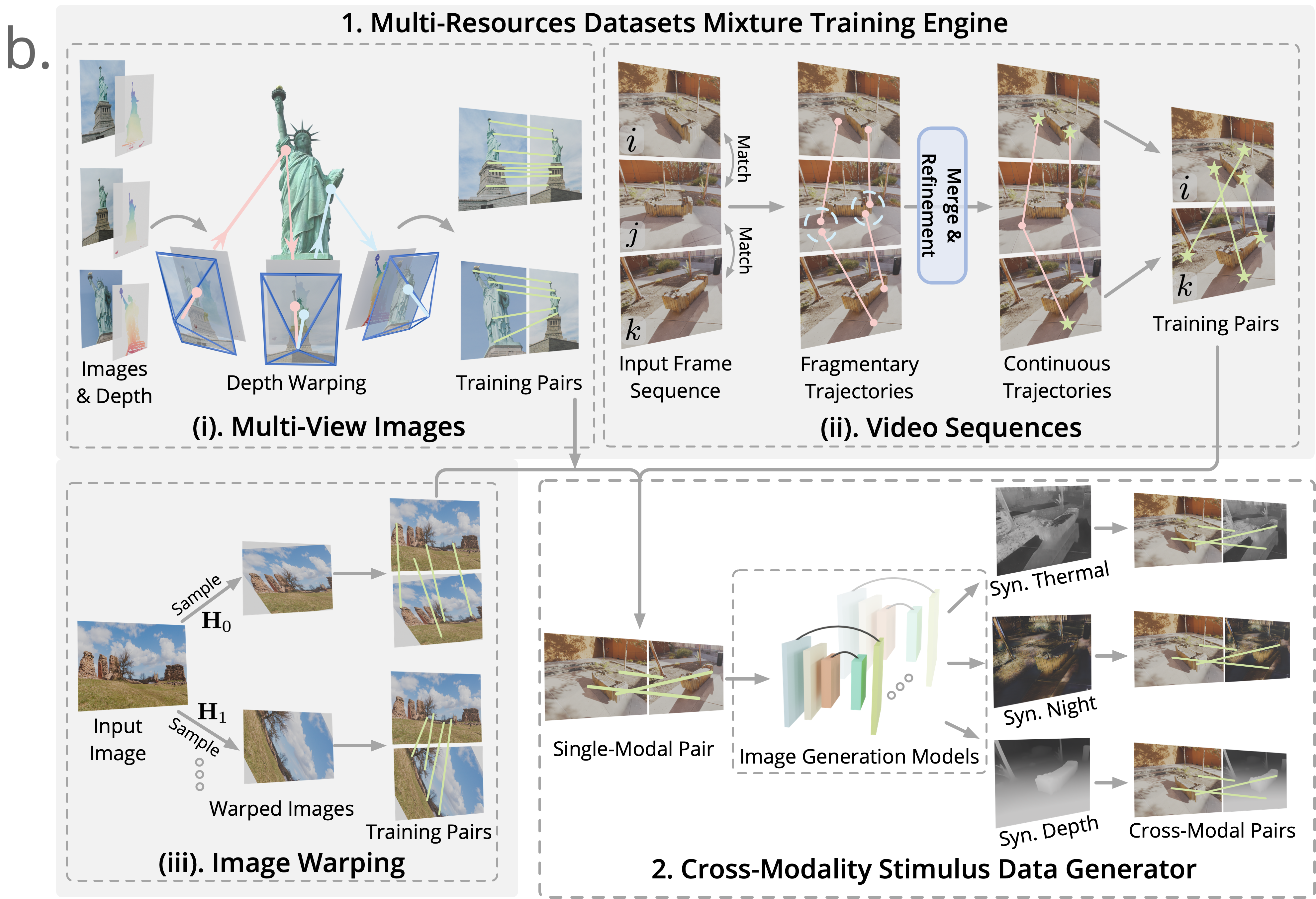
你可以把多资源数据融合想象成一个烹饪大餐的过程。为了做出一桌味道丰富、营养均衡的大餐,我们往往需要各种食材:蔬菜、肉类、水果、谷物……在图像匹配任务中,这些“食材”正是来自不同场景与数据来源的数据集。框架主要包含以下三大数据源:
多视角图像与几何数据集
利用场景重建获得的多视角图像可以通过深度图和相机参数,计算出精确的像素对应关系。简单来说,就是通过已知的深度信息和投影函数,将二维图像中的点“抬升”到三维,再映射到另一视角。计算公式为:
其中, 表示投影矩阵, 为左右视角之间的相对姿态。接着,通过计算深度误差 和循环投影误差 来筛选出高质量的匹配对:
如果 且 小于 3 像素,则保留这对匹配点。通过这种方式,来自 MegaDepth、ScanNet++、BlendedMVS 等数据集的图像对为模型提供了真实且精确的匹配信号。视频序列中的连续镜头
视频序列可以看作是时间的“长卷”,其中每一帧之间具有连续性。利用这一特性,通过构造粗到细的点轨迹,可以在长距离帧间找到有效的匹配对。简单来说,就是先用粗略匹配方法(例如 ROMA 模型)匹配相邻帧,再利用滑动窗口(7×7)进行非极大值抑制,合并零散的匹配点,随后经过 Transformer 多视图细化,获得亚像素级别的精准匹配。这样的策略不仅能捕捉视角大幅变化下的对应信息,还能自动构建长距匹配轨迹。单幅图像中的仿射变换
当我们从互联网上获取单幅图像时,虽然它们没有提供真实的视角信息,但通过随机采样齐次坐标的旋转、平移、缩放、切变等仿射变换,我们可以合成出不同视角的图像对。用这些变换生成的图像对,虽然仅限于平面变换,却能为模型提供丰富的结构信息,从而帮助其理解图像几何结构。另外,为缓解天空等区域的深度估计不准确问题,研究人员采用了一定的数据预处理策略,从而确保训练过程的稳定性。
通过上述多种数据源的并行训练,MatchAnything 框架能够在 800M 多对图像对上进行预训练,从而获得强大的跨模态匹配能力。
 跨模态刺激信号:打破外观壁垒的秘密武器
跨模态刺激信号:打破外观壁垒的秘密武器
与传统的仅依靠“光学”数据不同,这项方法在预训练阶段还引入了跨模态刺激信号。可以把这看作是一种“换装”技术,将一张原始的可见光图像通过图像风格转换或单目深度估计生成其在其他模态下的版本——例如合成出热成像、夜视或深度图。这样一来,模型在训练过程中便会接触到来自多种表观差异极大的图像对,但它们共享相同的基础结构信息。
例如,利用 CycleGAN 模型可以实现可见光到热成像的转换,该方法依靠循环一致性损失(cycle consistency loss)确保生成图像在形态上与原图保持一致,但颜色、纹理等外观特征却发生了巨大变化。模型因此被迫“去除”光照、色彩等表观信息,而专注于捕捉图像的内在几何结构,这正是跨模态匹配所需要的核心能力。
同样,利用单目深度估计网络(如 DepthAnything),将可见光图像转换为深度图,可以引入更显著的结构性变化。通过这种方式,模型学会忽略材质、纹理等影响,牢牢把握住物体的形状与空间分布信息,从而在后续面对真实的跨模态数据时,仍能准确匹配对应区域。
这种“以假乱真”的跨模态刺激方式,犹如在模型训练过程中进行了一次精彩的“换装舞会”,让模型不仅见识了传统的“正装”可见光图像,更体验了各种风格迥异的“潮流造型”。正因如此,即便在实际应用中遇到完全陌生的模态(如医用 CT 与 MR、热成像与可见光),模型依旧能够发挥其“看本质”的能力,实现精准匹配。
 探索最前沿:检测器自由匹配器的构建与优势
探索最前沿:检测器自由匹配器的构建与优势
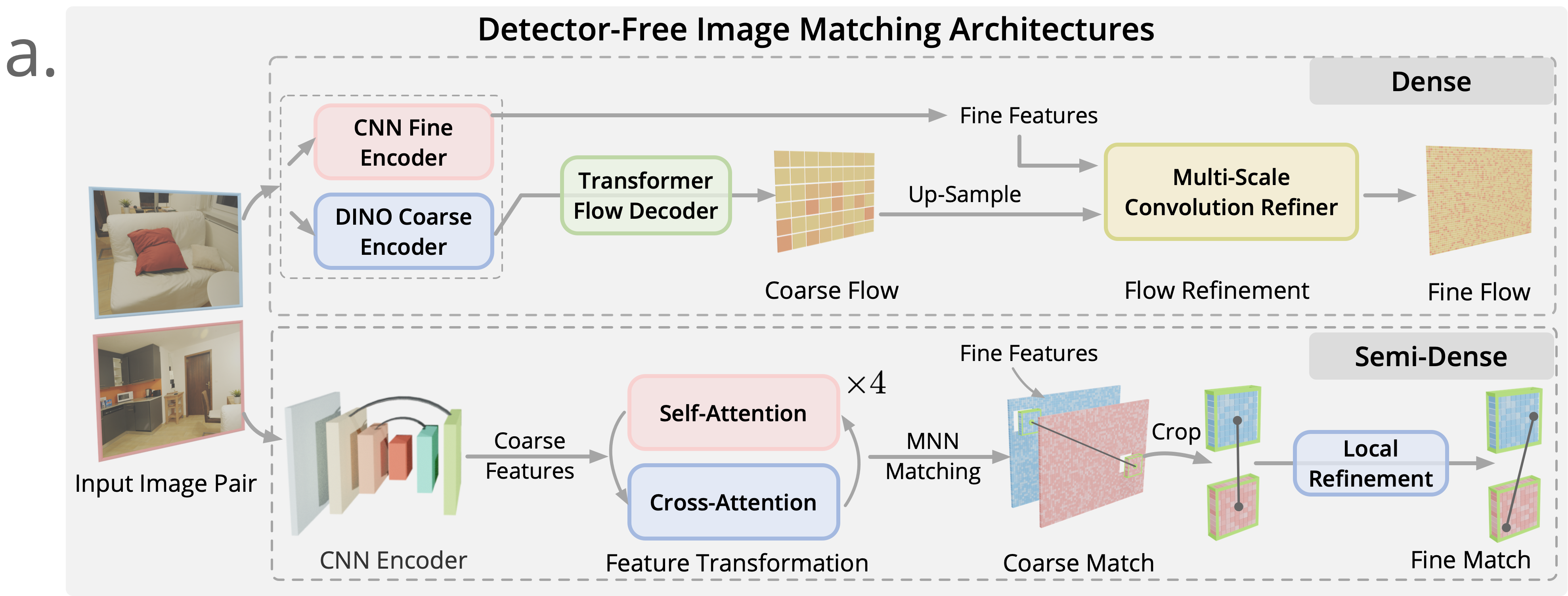
传统图像匹配方法往往基于关键点提取——从一幅图像中先检测出具有显著语义的点,再计算其局部描述子,最后采用最近邻搜索进行匹配。然而,这种方法在跨模态场景下容易受到外观差异的干扰,导致初期检测不到足够稳定的关键点。为了解决这一问题,近年来基于 Transformer 的检测器自由(detector-free)匹配方法崭露头角。
 检测器自由匹配器的重要性
检测器自由匹配器的重要性
检测器自由匹配器的核心思想在于绕开传统的关键点检测步骤,直接进行像素级别的匹配。举个简单的例子,就好比在找朋友时不再只依靠面部特征,而是结合身高、步态、服饰甚至说话方式等多种信息,综合判断两人是否为同一人。这种方法能够更全面地提取图像中的信息,从而在面对光照、色彩、纹理等方面的巨大变化时,依然保持稳健性。
MatchAnything 框架中选用了两种具有代表性的检测器自由匹配模型:
密集匹配器 ROMA
ROMA 模型采用了粗-细分层结构:首先利用预训练的 DINOv2 提取粗略特征,再通过 Transformer 解码器预测粗糙的位移场,即“粗匹配”;
接着,利用 CNN 提取细粒度图像特征,通过卷积细化网络逐步精细化位移场,实现亚像素级别的精确匹配。
这种方法使得 ROMA 在处理具有大幅视角变化或者外观差异的图像时,表现得尤为出色。事实上,在一些医疗图像匹配任务中,ROMA 在 Harvard Brain 数据集上就实现了高达 76.9% 的相对提升。
半密集匹配器 ELoFTR
ELoFTR 模型则充分利用了 Transformer 的自注意力机制,在下采样的粗特征图上构建全局关联信息,并通过多尺度、局部细化来达到高效匹配。这种半密集匹配器在保证匹配精度的同时,又兼顾了计算效率。事实上,其匹配速度令人印象深刻——在一对 640×480 分辨率的图像上,仅需约 40 毫秒即可完成匹配任务。
正是因为这两种匹配器在结构上具有互补性,MatchAnything 框架通过大规模预训练,使得二者均能够在跨模态任务中实现惊人的通用性。特别值得一提的是,同一网络权重在多个全新场景(如从 CT 到 MR、从热成像到可见光等)中均能零样本迁移,达到优异表现,这无疑为跨模态图像匹配开拓了崭新的应用前景。
 实验验证:千锤百炼中的性能突破
实验验证:千锤百炼中的性能突破
科技的发展总是离不开严谨的实验验证。MatchAnything 框架经过在九个真实数据集、八项跨模态注册任务上的大量实验,展示了其出色的通用性和高精度匹配能力。下面,我们将用生动的实验案例,带您一览这一技术在各个领域中的逆袭之路。
 医疗影像中的精确匹配
医疗影像中的精确匹配
在医疗诊断领域,医师常常需要对来自 CT、MR、PET、SPECT 等不同成像模态的图像进行精准对齐。以 Harvard Brain 数据集为例,该数据集中包含 810 对脑部影像,并涉及多种模态对(CT-MR、PET-MR、SPECT-MR)。在这种情况下,传统匹配方法很容易受到纹理、噪声及成像机制间巨大外观差异的影响,难以获得稳定匹配。而采用预训练后的 ROMA 模型,在对这组数据进行匹配时,实验数据显示其成功率指标大幅提高,达到前所未有的 76.9% 相对提升。
此外,在 Liver CT-MR 数据集上,ELoFTR 模型更是展现了 423.7% 的显著改进。这样的实验结果不仅证明了预训练框架在医疗影像匹配上的巨大潜力,也为多模态影像融合和智能诊断提供了可靠的技术支撑。
 组织病理学的形态对应
组织病理学的形态对应
在病理图像匹配任务中,不同染色(如 H&E 与 IHC)的图像常常存在较大的外观变化。然而,病理学家需要将这些图像进行对齐,以便获得细胞结构和微观病变的全貌。通过使用 ANHIR 挑战数据集,MatchAnything 模型不仅在刚性匹配上达到了优化效果,而且在非刚性形变补偿上也表现卓越。结果显示,经过预训练的模型在所有指标上均优于传统方法,ELoFTR 模型在某些指标上更是达到了 55.3% 的相对改进,极大地推动了病理图像自动分析技术的发展。
 视网膜影像对齐的应用
视网膜影像对齐的应用
视网膜影像匹配对于眼科疾病检测尤为重要。FIRE 数据集中包含 134 对来自不同视角的视网膜图像,通过精确匹配,医生可以获得一个全景视图,从而更准确地判断疾病病灶的位置和分布。实验结果表明,即使在传统单模态任务中,经过跨模态预训练的 ROMA 模型仍然能取得与专为视网膜匹配设计的 SuperRetina 相当甚至更优的表现,证明跨模态训练不仅提高了模型的泛化能力,还使得其在单模态任务中亦能保持竞争力。
 热成像与可见光的完美融合
热成像与可见光的完美融合
在无人驾驶、灾害监测和城市热管理等领域,热成像与可见光图像的匹配至关重要。匹配任务要求模型既能捕捉热成像中的温度分布特征,又能兼顾可见光图像中的细节纹理。MatchAnything 模型在 Visible-Thermal 数据集上表现突出:在卫星视角数据上,ROMA 模型达到 74.2% 的成功率,而在 UAV 拍摄的航空视角中,取得了显著的相对提升。这些数据不仅证明了框架在全天候、多场景下的鲁棒性,也为实现多传感器数据融合打开了新局面。
 SAR 与矢量地图匹配:挑战中的异军突起
SAR 与矢量地图匹配:挑战中的异军突起
最后,有趣的是,在 SAR(合成孔径雷达)图像与可见光图像、甚至矢量地图与可见光图像的匹配任务中,常规方法由于训练数据不足而表现欠佳。然而,经过预训练的模型凭借其强大的跨模态泛化能力,展现出令人瞩目的性能。在 SAR 与可见光匹配任务中,ROMA 和 ELoFTR 模型分别取得了高达 93.3% 和 72.5% 的成功率;而在矢量地图与可见光影像匹配中,成功率达到了 90.4% 至 77.2%,这些指标表明预训练框架能够有效鼓励模型学习到更为普适的图像几何结构信息,从而在面对完全未知的匹配任务时依然保持高水平表现。
另外,关于速度方面,虽然 ROMA 模型在处理一对 640×480 图像时约需 303 毫秒,而 ELoFTR 则仅需要 40 毫秒,这也证明了在效率与精度之间达到了良好的平衡。
 方法论背后的技术细节:从架构到训练策略
方法论背后的技术细节:从架构到训练策略
为了实现上述优异性能,MatchAnything 框架在模型设计、数据预处理、损失函数选择以及训练流程等多个步骤中都进行了精心设计与调优。以下是其中几个关键技术点的深入解析:
 Transformer 架构与自注意力机制
Transformer 架构与自注意力机制
检测器自由匹配方法的核心在于 Transformer 架构。该架构利用自注意力机制(self-attention)能够捕捉图像全局信息,使得模型在构建像素间的长距离关联时无往不利。以 ELoFTR 模型为例,其实现了全局与局部信息的高效融合,从而在粗特征阶段便构建出密集匹配图片信息,随后利用局部微调进一步优化到亚像素级。这种“粗到细”的匹配流程不仅提高了匹配精度,同时也为跨模态应用提供了足够的鲁棒性。
 多资源联合训练的体系结构
多资源联合训练的体系结构
为了充分利用不同数据资源的优势,MatchAnything 框架设计了一个混合训练引擎,将来自多视角图像、视频序列、以及单幅图像仿射变换生成的数据合并为一个统一的训练数据集。图中可以形象地表示为:
┌─────────────────────────────┐
│ 多视角图像与几何信息 │
└─────────────┬───────────────┘
│
▼
┌─────────────────────────────┐
│ 视频序列与长距匹配 │
└─────────────┬───────────────┘
│
▼
┌─────────────────────────────┐
│ 单幅图像仿射变换生成 │
└─────────────┬───────────────┘
│
▼
综合训练大数据集这种混合数据训练策略确保了数据的多样性,使模型能够在面对各种场景和视角变化时保持稳定性能。实际上,多资源联合训练带来的效果远超单一数据源的累加,其原因在于不同数据类型之间存在着互补信息,能够更好地捕捉到图像的内在结构特征。
 交叉验证与精细调优
交叉验证与精细调优
MatchAnything 团队在训练过程中还设计了多种交叉验证方案和消融实验。例如,通过对比使用与不使用跨模态刺激信号时的性能变化,发现仅靠常规的光学图像增强手段(如亮度、对比度、模糊等变换)无法达到显著效果,而采用合成热成像、夜视图像以及深度图作为跨模态数据,则能大幅提升各项指标。关于视频数据,使用粗到细的匹配策略不仅延长了匹配轨迹,更提高了匹配的总体精度。实验数据表明,这种方法在 Visible-Thermal 数据集和 SAR 数据集上分别带来了 128.9% 和 207.5% 的相对性能提升。
对于模型调优,作者还在论文中详细讨论了在 16 台 NVIDIA A100-80G GPU 上,如何通过 AdamW 优化器以及特定的初始学习率(8×10⁻³)对 ELoFTR 与 ROMA 分别进行训练,从而在 4-6 天内获得高质量预训练模型。这种高效训练方式,使得同一网络权重不仅能够在多个跨模态任务中直接使用,还大幅减少了对任务特定微调的依赖。
 讨论与展望:未来科技的无限可能
讨论与展望:未来科技的无限可能
正如古往今来无数科学家不断追问“为何”与“如何”,MatchAnything 项目在实现跨模态匹配的过程中,也带来了一系列新的问题与思考。尽管预训练框架在大部分跨模态任务中表现卓越,但在极端情况下,如航拍视图与地面视图之间匹配时,由于视角及外观的巨大差异,模型的性能仍然有所下降。对此,研究人员提出了未来可以通过微调少量标注数据(例如采用 LoRA、ControlNet 等技术)来进一步强化模型在特定任务下的表现。
此外,跨模态匹配的成功,也为人工智能在医学诊断、智能交通、环境监测等领域的应用开辟了新天地。试想在未来,医生能够通过自动匹配多种医学影像,迅速获得准确的诊断信息;在灾害救援中,监控中心可以实时融合卫星、热成像和无人机图像,迅速判断灾情;在自动驾驶领域,车辆传感器所采集的多模态数据将无缝融合,打造出更为智能、安全的驾驶系统。这一切都是跨模态图像匹配技术赋予我们的无限想象空间。
最后,不得不提的是,MatchAnything 框架的研究成果不仅是技术上的一大突破,更代表了一种新范式:通过大规模数据预训练与跨模态数据生成,我们可以训练出更具普适性与鲁棒性的模型。这种思路,有望扩展到更多人工智能任务中,推动 AI 从“局部聪明”到“全局智慧”的蜕变。
 结语
结语
从宏观的应用场景到微观的数学公式,从多源数据的混合训练到跨模态刺激信号的巧妙设计,MatchAnything 项目无疑是一场技术与艺术的双重盛宴。它不仅展示了如何打破传统图像匹配方法的局限,更向我们呈现了一幅未来科技的宏伟蓝图——一个在多模态数据海洋中自由穿梭、精准定位的智能世界。
正如本文开头提到的那样,图像匹配技术在科学、工程、医疗、安防等各个领域都有着举足轻重的地位。通过本研究,我们不仅看到了跨模态匹配技术的巨大潜力,更感受到了科技进步对人类生活带来的深远影响。未来,当计算机能够轻松地理解和匹配各种模态的图像时,我们将见证到一个更加智能、高效且互联互通的世界。
在这个挑战与机遇并存的时代,MatchAnything 为我们提供了一个全新的思路——用大量合成数据和巧妙设计的预训练策略,让模型学会“看本质”,最终实现跨越各种模态的精准匹配。正如那座连接不同星系的桥梁,它将为未来的人工智能研究指明道路,引领我们走向一个无限可能的新时代。
 精简参考文献
精简参考文献
- He, X. et al. “MatchAnything: Universal Cross-Modality Image Matching with Large-Scale Pre-Training.” arXiv preprint arXiv:2501.07556, 2025.
- Dosovitskiy, A. et al. “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.” 2020.
- Ronneberger, O. et al. “U-Net: Convolutional Networks for Biomedical Image Segmentation.” 2015.
- Zhu, J.Y. et al. “Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks.” ICCV, 2017.
- Carion, N. et al. “End-to-End Object Detection with Transformers.” ECCV, 2020.